저는 한 페이지의 결과 수를 10으로 설정했기 때문에 한 페이지 내에 총 10개의 결과물이 나와야하지만 9월 2일 날에는 9개의 태풍정보가 있었기 때문에 9개가 출력되었습니다.
아래는 9개의 태풍정보 중 일부분입니다.
20.09.02의 태풍정보조회
위와 같이 9월 2일 당일날 아침부터 자정까지 발령됐던 태풍의 정보와 시간, 태풍번호, 통보문 발표 호수를 알 수 있었습니다.
이 날에는 하루종일 태풍 경로가 울렸습니다. 눈으로 직접 확인해보니 정말 하루종일 태풍 알림이 있었다는 것을 알 수 있었습니다.
5-4. 태풍예상정보조회
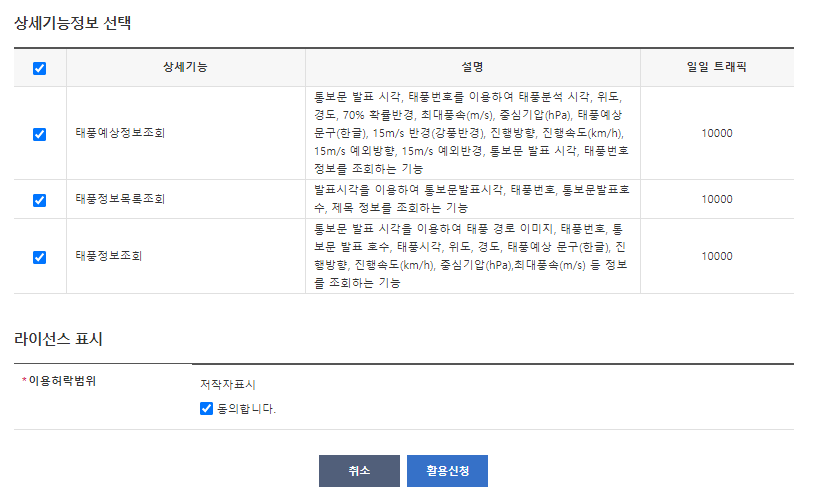
태풍예상정보조회_상세기능정보
태풍예상정보는 통보문 발표 시각, 태풍번호를 이용하여 태풍분석 시각, 위도, 경도, 70% 확률반경, 최대풍속(m/s), 중심기압(hPa), 태풍예상 문구(한글), 15m/s 반경(강풍반경), 진행방향, 진행속도(km/h), 15m/s 예외방향, 15m/s 예외반경, 통보문 발표 시각, 태풍번호 정보를 조회하는 기능입니다.
call back url : apis.data.go.kr/1360000/TyphoonInfoService/getTyphoonFcst
url에 요청 메시지 명세에 맞는 값들을 넣어 요청하면 원하는 결과를 얻을 수 있습니다.
요청 메시지 명세
요청 메시지 명세를 넣은 url 예시입니다.
apis.data.go.kr/1360000/TyphoonInfoService/getTyphoonFcst?serviceKey=인증키&pageNo=페이지번호&numOfRows=한 페이지 결과 수&dataType=응답자료형식(XML/JSON)&tmFc=발표시각(년월일시분)&typSeq=태풍번호&
call back url에 본인이 얻고자 하는 값들을 넣어 요청하게 된다면 아래와 같은 응답 메시지 명세를 얻을 수 있습니다.
맨 하단에 '기상청22 태풍정보 조회서비스 오픈API활용가이드v2.docx'이 참고문서를 다운받아줍니다!
한마디로 api를 사용하는 방법과 데이터의 정보에 대해서 알려주는 문서입니다.
5. 참고문서 정보 확인 및 인증키 확인
open api 활용가이드참고문서 목차
파일을 클릭해보시면 'open api 할용가이드'라고 적혀진 파일을 받아보셨을겁니다. 이제 차근차근 내려가면 확인해보도록하죠!
5-1. 전체적인 api 서비스 개요
상세기능정보 선택
저희가 활용신청과정에서 상세기능정보 선택하신게 기억이 나시나요? '태풍정보 조회서비스'가 총 3가지의 데이터를 제공하고있는데 저는 3개 모두 선택을 했기 때문에 발급받은 인증키로 저 세 개의 데이터를 모두 활용할 수 있다는 뜻입니다.
태풍정보 조회서비스
이 자료는 태풍정보 조회서비스로 태풍정보, 태풍정보목록, 태풍예상정보를 조회하는 서비스 입니다.
보시면 서비스 인증방법이'서비스 key'라고되어있는데 이 말은 서비스 key만 있으면 된다는 표시입니다. 또한 교환 데이터 표준은XML을 제공한다고 되어있습니다. 인터페이스 표준은 'REST(GET, POST, PUT, DELETE) 방식으로요청하라고 나와있습니다. 메시지 교환 유형은Request-Response라는 것을 알 수 있습니다.
상세기능 목록
서비스 URL을 보시면 이렇게 적혀있는데 apis.data.go.kr/1360000/TyphoonInfoServic/정보를 얻고자 하는 상세기능명
typhooninfoservic/여기에 저 3가지 정보들 가운데 본인이 얻고자 하는 데이터의 영문을 넣어서 url을 요청하면됩니다.
5-2. 태풍정보조회
상세기능정보
태풍정보조회 데이터는 통보문 발표 시각을 이용하여 태풍 경로 이미지, 태풍번호, 통보문 발표 호수, 태풍시각, 위도, 경도 등등 정보를 태풍의 정보를 조회하는 url입니다.
call back url : apis.data.go.kr/1360000/TyphoonInfoService/getTyphoonInfo
이 링크에 값을 넣어서 요청하면 원하는 자료를 응답받을 수 있습니다.
여기서 gettyphooninfo는 아래 요청 메시지 명세에 대한 정보를 입력해서 넣으면 됩니다.
요청 메시지 명세
예시로는
http://apis.data.go.kr/1360000/TyphoonInfoService/getTyphoonInfo?serviceKey=인증키&numOfRows=한 페이지 결과수&pageNo=페이지 번호&dataType=응답자료형식(XML/JSON)&fromTmFc=통보문발표시각(년월일)&toTmFc=통보문발표시각(년월일)
이런식으로 info부분에 요청 메시지 명세에 대한 값들과 함께 적으면 됩니다.
그 후에 링크를 검색하면 결과가 나오게되는데 결과를 보기전에 어떤 결과가 나오는지 목록을 확인해봤습니다.
- 왼쪽 트리를 보시면, 후원자 수가 74명보다 적고 최대 금액 후원자 수가 5명보다 적을 경우 실패한 프로젝트로 분류됩니다. 또한 서포트 단계 수가 5보다 작을 경우 실패한 프로젝트로 분류됩니다.
- 최소 금액 후원자 수가 1명보다 적으면 실패한 프로젝트로 분류됩니다. 여기서 최소 금액 후원자 수가 1명보다 많을 경우는 성공한 프로젝트로 분류됩니다.
- 오른쪽 트리를 보시면 후원자 수가 195명보다 많은 경우는 성공한 프로젝트를 분류됩니다. 또한 최대 금액 후원자 수가 6명보다 적을 경우는 성공한 프로젝트로 분류됩니다. 최소 금액 후원자 수가 1명보다 적을 경우 성공한 프로젝트로 분류되는 것을 볼 수 있었습니다.
entropy값은 0과 1사이의 값을 가지며 0.5에서 멀어질수록 잘 분류된 노드라고 할 수 있습니다.
feature importance 특성 중요도 확인하기
# 트리를 결정하는데 각 Feature의 중요도를 확인하기 위해 Feature importance를 이용
def plot_feature_importances(model):
n_features=df.data.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),df.feature_names)
plt.xlabel('importance_value')
plt.ylabel('feature')
plt.ylim(-1,n_features)
# 시각화하여 보기 쉽게 표현
#프로젝트의 성공여부에 크게 영향을 끼치는 Feature 확인
feature_importance_values = best_df_clf.feature_importances_
plot_feature_importances(clf)
#Feature importance 함수를 이용해 특성 중요도 확인
importance = clf.feature_importances_
#0은 전혀 사용되지 않았다는 뜻이고 1은 완벽하게 예측했다는 뜻
#backers, Maximum amount of sponsors, Minimum amount of sponsors, Number of projects opened 순으로 중요도 확인
importance_list = list(zip(x_train.columns,importance))
sorted(importance_list, key=lambda x:x[1],reverse=True)
feature importance 시각화 하여 확인
feature importance 값 확인
feature importance 특성 중요도를 이용해. Tree를 만드는 데 각 특성이 얼마나 중요한지 확인해보았습니다.
- x축에는 중요도의 값, y축에는 feature들의 이름을 나타냅니다.
- 시각화 결과, 후원자 수가 다른 feature들보다 월등히 높은 중요도를 보였습니다.
- 0은 전혀 사용되지 않았다는 뜻이고 1에 가까운 값일수록 완벽하게 예측했다는 뜻입니다.
- 프로젝트 제작자의 개설 횟수는 전혀 사용되지 않았고, 후원자 수가 tree를 만드는 과정에서 가장 크게 영향을 끼쳤다는 것을 볼 수 있었습니다.
- 5개의 feature 중 후원자 수, 최대, 최소 금액 후원자, 서포트 금액별 단계 개수 순으로 프로젝트의 성공과 실패에 중요했으며, 가장 큰 영향을 미친 feature는 후원자 수임을 알 수 있었습니다.
- 프로젝트의 개설 횟수는 프로젝의 성공실패여부에 영향을 끼치지 않았다는 것을 볼 수 있었습니다.
1. Backers(약 94%)
2. Maximum amount of sponsors(약 0.35%)
3. Minimum amount of sponsors(약 0.02%)
4. Total number of support steps(약 0.01%)
5. Number of projects opended(0%)
학교 과제로써 프로젝트를 진행했지만 과제를 하면서 아주 살-짝 재미있기도 했고 신기하기도했고..!
다음에도 종종 이런식으로 빅데이터 분석을 통해 의미있는 결과를 가져오겠습니다!
이번에는 첫 분석이라서 그런지 정확하지 않지만 그래도 ... 처음이니깐... 그냥 작은 비버가 한 단계 더 성장했구나! 라고 봐주세요.. 헿
[빅데이터] kickstarter에서 Project에 큰 영향을 미치는 Feature 확인하기(2. 전체 feature 수집 및 특정 feature 추출)
이번 포스팅은 저번 시간에 수집한 데이터들을 가지고 decision tree를 이용한 데이터 분석입니다.
수집한 데이터에서 분석에 유용하게 쓰일만한 특정 feature를 추출한 후 데이터 분석을 진행했습니다.
6. 분석 방법
6-1-1. 패키지 및 데이터 로드
첫 번째로 분석에 사용될 패키지를 로드하였습니다.
- 또 각 프로젝트의 상세 URL을 통해 수집한 feature 데이터를 로드했습니다.
#패키지 로드
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from IPython.core.display import Image
from sklearn.tree import export_graphviz
from sklearn import tree
from sklearn import metrics
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import graphviz
import pydot
import io
수집한 모든 featurer 가운데 특정 feature 추출
#수집한 모든 feature 불러오기
success_feature= pd.read_csv('./success_link_feature.csv',index_col=0)
fail_feature = pd.read_csv('./fail_link_feature.csv',index_col=0)
success_feature
#성공, 실패한 Feature들을 concat으로 붙이기
#성공(120개), 실패(117개), 총 237개의 데이터 수집
df = pd.concat([success_feature, fail_feature],ignore_index=True)
# 모든 Feature 중에서 수치화 할 수 있는 Feature 추출하기
df = df[['backers','Number of projects opened','Total number of support steps','Maximum amount of sponsors','Minimum amount of sponsors','label']]
6-1-2. 속성과 클래스 분리
두 번째로는 속성과 클래스를 분리했습니다.
- DF_label로 프로젝트의 성공 여부 라벨을 변수에 넣고, 수집된 feature들 중 선별한 5개 feature를 DF 변수에 넣었습니다.
# df_label에는 label(성공, 실패)값을, df에는 나머지 수치화 값들을 넣어준다
df_label= df[['label']]
df = df[['backers','Number of projects opened','Total number of support steps'
,'Maximum amount of sponsors','Minimum amount of sponsors']]
# 분석에 사용하기 위해서 데이터의 형태를 바꿔주는 작업을 진행
# 데이터의 수치 값들을 float형으로 변환시킨 후, int형으로 변환시킨다.
df_label['label'] = df_label['label'].astype(str)
df=df.replace(',','',regex=True).astype(float)
df = df.astype(int)
df
int형으로 변환된 df
후에 Decision tree에 해당 변수들을 넣기위해 변수 이름 다시 정의해서 값 넣기
# 데이터들을 쉽게 확인하기 위해 데이터 정리
df.feature_names = df.columns
df.target_names = np.array(['fail', 'success'])
df.data = df.values
df.target = df_label.label
#학습과 테스트 데이터 세트로 분리
# trian data 189개, test data 48개
x_train, x_test, y_train,y_test = train_test_split(df,df_label,train_size = 0.8)
x_train
x_train 데이터
6-1-3. 데이터 학습
세 번째로 데이터를 학습시켰습니다.
- 로드된 의사결정 트리 분류 모듈을 변수 clf에 저장했습니다.
- 오버피팅을 방지하기 위해 깊이는 5로 설정했습니다.
- clf의 함수 fit 함수에 변수 x_train, y_train을 입력해 의사결정 트리 분류 모델을 생성, 학습시켰습니다.
# DecicionTreeClassifier 생성(max_depth = 5 으로 제한) - 오버피팅 방지
clf=tree.DecisionTreeClassifier(max_depth=5,criterion='entropy',random_state=0)
# DecisionTreeClassifier 학습
clf.fit(x_train,y_train)
Decisiontreeclassifier생성
6-1-4. Decision tree 그래프 표현 및 Feature importance 시각화
네 번째로 의사결정 트리와 feature importance를 시각화시켰습니다.
- Tree 패키지 중 의사결정 트리를 dot 형식으로 내보내는 함수인 export_graphviz() 를 이용해 트리 표현을 함수로 만들었습니다.
# 트리를 결정하는데 각 Feature의 중요도를 확인하기 위해 Feature importance를 이용
def plot_feature_importances(model):
n_features=df.data.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),df.feature_names)
plt.xlabel('importance_value')
plt.ylabel('feature')
plt.ylim(-1,n_features
# 트리를 확인하기 위한 함수
def draw_decision_tree(model):
dot_buf = io.StringIO()
export_graphviz(clf, out_file=dot_buf, feature_names=df.feature_names,
class_names=df.target_names, filled=True,rounded=True)
graph = pydot.graph_from_dot_data(dot_buf.getvalue())[0]
image = graph.create_png()
return Image(image)
- feature_names는 각 features의 이름, class_names는 각 대상 class의 이름을 오름차순으로 정렬, filled는 True일 경우 분류를 위한 다수 클래스, 회귀 값의 극한 또는 다중 출력의 노드 순도를 나타내기 위해 노드를 색칠한다.
여기서는 함수에 대한 자세한 내용은 적지 않았습니다. 관심있으신 분들은 검색해보면서 실습해보시는거 추천드려요!!
참 분석이라는건 방대한 것 같아요.. 하면서 새로운 내용 발견하고,,, 하다가 또 다른 방법들도 보이고,, 다른 결과들도 나오고,,, 그만큼 많은 지식을 요하는 부분이라는 거겠죠..!!
다음시간에는 Decision tree를 이용해서 데이터 분석한 결과에 대해서 포스팅 하겠습니다.
오늘도 긴 글 읽어주셔서 감사드립니다.
행복한 하루 보내시길 바랄께요~
[빅데이터] kickstarter에서 Project에 큰 영향을 미치는 Feature 확인하기(4. Decision tree 결과 분석)
[빅데이터] kickstarter에서 Project에 큰 영향을 미치는 Feature 확인하기(1. 상세사이트 링크 수집)
5. 수집된 링크에서 feature 수집
상세 사이트에서 프로젝트 링크, 실제로 모인 금액, 목표 금액, 제작자 이름 등등 프로젝트 성공 여부에 영향을 미쳤을 만한 모든 feature를 수집하였습니다.
- 이 중에서 수치화를 통해 영향을 측정할 수 있는feature를 5개로 추려내어 학습을 진행하였습니다.
- 이번 포스팅에서는 모든 feature를 수집하는 것에 대해 설명드리겠습니다.
1) 수집한 feature : 프로젝트 링크 , 실제로 모인 금액 , 목표 금액 , 제작자 이름 , 제작자 지역 , 프로젝트 장르 , 서포트 단계별 금액 리스트 , 서포트 최고, 최소 금액 , 서포트 단계별 금액 후원자 수
2) 추려낸 5개의 feature : 총 후원자수 , 제작자 프로젝트 개설횟수 , 서포트 금액 단계별 총 개수 , 서포트 최고 금액 후원자 수 , 서포트 최소 금액 후원자 수 (3번째 포스팅 참고)
프로젝트의 크라우드 펀딩 페이지
5-1. 성공한 프로젝트의 상세 사이트에서 feature수집
5-1-1. 전체 feature 수집
# 수집되는 Featrue들을 넣기 위해 각 Feature별로 리스트 생성
money_list=[]
pledged_money_list=[]
creator_list=[]
backers_list=[]
final_created_list=[]
city_list=[]
category_list=[]
support_bankroll_list=[]
support_max_money_list=[]
support_min_money_list=[]
support_max_backers_list=[]
support_min_backers_list=[]
level_num_list=[]
support_backers_list=[]
for i in range(len(success_link_list)):
url = success_link_list[i]
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
print("링크",url)
#실제로모인금액
money = soup.select('span.money')[0].text
money = re.findall('\d+',money)
money = "".join(money)
money_list.append(money)
print("모인금액",money)
#목표금액
pledged_money = soup.select('span.money')[2].text
pledged_money = re.findall('\d+',pledged_money)
pledged_money = "".join(pledged_money)
pledged_money_list.append(pledged_money)
print("목표금액",pledged_money)
#만든사람
creator = soup.select('a.hero__link')[1].text
creator = creator.strip()
creator_list.append(creator)
print("만든사람",creator)
#후원자수
backers = soup.select('h3.mb0')[1].text
backers = backers.strip()
backers_list.append(backers)
print("총 후원자수",backers)
#제작자의프로젝트개설횟수
a_tags = soup.find_all("a", {'class':"hero__link remote_modal_dialog js-update-text-color"})
for created in a_tags :
print(created["href"]) # 찾은 a태그의 href 값 크롤링
url = "https://www.kickstarter.com" + created["href"]
driver.get(url)
html_s = driver.page_source
soup_s = BeautifulSoup(html_s, 'html.parser')
created_dummy = driver.find_element_by_class_name("created-projects.py2.f5.mb3")
final_created = re.findall('\d+',created_dummy.text)
for i in range(len(final_created)):
final_created[i] = int(final_created[i])
if len(final_created) == 1:
created_num = 0
else:
created_num = final_created[0]
final_created_list.append(created_num)
print("개설횟수",final_created_list)
#제작자지역
city = soup.select('a.grey-dark')[4].text
city = city.strip()
city_list.append(city)
print("제작자지역",city)
#프로젝트장르
category = soup.select('a.grey-dark')[5].text
category = category.strip()
category_list.append(category)
print("장르",category)
#서포트금액
support_money = soup.select('span.money')
support_bankroll = []
for line in support_money:
line = line.get_text()
line = re.findall('\d+',line)
line = "".join(line)
support_bankroll.append(int(line))
for i in range(3):
support_bankroll.pop(0)
support_bankroll_list.append(support_bankroll)
print("서포트금액",support_bankroll)
#서포트금액 최소/최대
support_max_idx = 0
support_min_idx = 0
max = support_bankroll[0]
min = support_bankroll[0]
for i in range(len(support_bankroll)):
if max < support_bankroll[i]:
max = support_bankroll[i]
support_max_idx = i
if min > support_bankroll[i]:
min = support_bankroll[i]
support_min_idx = i
print("최대금액",max)
print("최소금액",min)
support_max_money_list.append(max)
support_min_money_list.append(min)
#단계개수
level_num = len(support_bankroll)
level_num_list.append(level_num)
print("서포트 단계",level_num)
#서포트후원자수
support_backer = soup.select(' div > div > div > div > div > div > div > ol > li > div > div > span')
support_backers = []
for line in support_backer:
line = line.get_text()
if line == 'Includes:':
continue
line = line.replace('\n','')
if line == 'Limited':
continue
if line == 'Reward no longer available':
continue
line = line.replace(' backers','')
line = line.replace(' backer','')
support_backers.append(line)
support_backers_list.append(support_backers)
print("서포트 금액별 후원자수",support_backers)
#서포트최소/최대후원자수
a_ar = np.array(support_bankroll)
max_money_index = np.argmax(support_bankroll)
min_money_index = np.argmin(support_bankroll)
max_money_backers = support_backers[max_money_index]
min_money_backers = support_backers[min_money_index]
support_max_backers_list.append(max_money_backers)
support_min_backers_list.append(min_money_backers)
print("최대 금액 후원자수",max_money_backers)
print("최소 금액 후원자수",min_money_backers)
print("\n")
전체 feature 수집되는 형식
성공한 프로젝트 모든 feature 수집 코드를 돌린 후 나오는 결과
5-1-2. csv파일로 수집한 모든 featrue 저장
import pandas as pd
success_list = []
result = []
for money_list,pledged_money_list,creator_list,backers_list,final_created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list in zip(money_list,pledged_money_list,creator_list,backers_list,final_created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list):
success_list = [money_list,pledged_money_list,creator_list,backers_list,final_created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list]
result.append(success_list)
df = pd.DataFrame(result, columns = ['money','pledged_money','creator','backers','Number of projects opened','Producer area','genre','Support amount list','The highest amount of support','The minimum amount of support','Total number of support steps','List of supporters','Maximum amount of sponsors','Minimum amount of sponsors'])
df.to_csv('success_link_feature.csv',encoding = 'utf-8-sig')
for i in range(len(fail_link_list)):
url = fail_link_list[i]
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
print('링크',url)
time.sleep(8)
#실제로모인금액
money = soup.select('span.soft-black')[1].text
money= re.findall('\d+',money)
money= "".join(money)
money_list.append(money)
print('실제로 모인 금액',money)
time.sleep(0.2)
#목표금액
pledged_money = soup.find('span',{'class':'inline-block hide-sm'}).text
pledged_money= re.findall('\d+',pledged_money)
pledged_money= "".join(pledged_money)
pledged_money_list.append(pledged_money)
print('목표금액',pledged_money)
time.sleep(0.2)
#제작자이름
creator = soup.select('div.text-left')[1].text
creator_list.append(creator)
print('제작자이름',creator)
#후원자수
time.sleep(0.2)
backers = soup.select(' div > div > div > div > div.flex.flex-column-lg.mb4.mb5-sm > div.ml5.ml0-lg.mb4-lg > div > span')[0].text
backer_list.append(backers)
print('후원자수',backers)
time.sleep(0.2)
#제작자의프로젝트개설횟수
created= soup.select('div.text-left')[2].text
final_created= re.findall('\d+',created)
for i in range(len(final_created)):
final_created[i]=int(final_created[i])
if len(final_created)==1:
created_num=0
else:
created_num=final_created[0]
created_list.append(created_num)
print('제작개설횟수',created_num)
#time.sleep(0.2)
#제작자지역
city = soup.select('span.ml1')[1].text
city_list.append(city)
print('제작자지역',city)
time.sleep(0.2)
#프로젝트장르
category = soup.select('span.ml1')[0].text
category_list.append(category)
print('프로젝트 장르',category)
time.sleep(0.2)
#서포트금액
support_money = soup.select('div.NS_projects__content > section.js-project-content.js-project-description-content.project-content > div > div > div > div.col.col-4.max-w62.sticky-rewards.z10 > div > div.mobile-hide > div > ol > li > div.pledge__info > h2 > span.money')
support_bankroll=[]
for line in support_money:
line=line.get_text()
line= re.findall('\d+',line)
line = "".join(line)
support_bankroll.append(int(line))
support_bankroll_list.append(support_bankroll)
print('서포트금액', support_bankroll)
time.sleep(0.2)
#서포트후원자수
support_backer = soup.select('div.NS_projects__content > section.js-project-content.js-project-description-content.project-content > div > div > div > div.col.col-4.max-w62.sticky-rewards.z10 > div > div.mobile-hide > div > ol > li > div.pledge__info > div.pledge__backer-stats > span')
support_backers = []
for line in support_backer:
line = line.get_text()
if line == 'Includes:':
continue
line = line.replace('\n','')
if line == 'Limited':
continue
if line == 'Reward no longer available':
continue
line = line.replace(' backers','')
line = line.replace(' backer','')
support_backers.append(line)
support_backers_list.append(support_backers)
print("서포트 금액별 후원자수",support_backers)
time.sleep(0.2)
#단계개수
level_num=len(support_bankroll)
level_num_list.append(level_num)
print('단계',level_num)
time.sleep(0.2)
#서포트금액 최소/최대
support_max_idx = 0
support_min_idx = 0
max = support_bankroll[0]
min = support_bankroll[0]
for i in range(len(support_bankroll)):
if max < support_bankroll[i]:
max = support_bankroll[i]
support_max_idx = i
if min > support_bankroll[i]:
min = support_bankroll[i]
support_min_idx = i
print("최대금액",max)
print("최소금액",min)
support_max_money_list.append(max)
support_min_money_list.append(min)
time.sleep(0.2)
#서포트최소/최대후원자수
a_ar = np.array(support_bankroll)
max_money_index = np.argmax(support_bankroll)
min_money_index = np.argmin(support_bankroll)
max_money_backers = support_backers[max_money_index]
min_money_backers = support_backers[min_money_index]
support_max_backers_list.append(max_money_backers)
support_min_backers_list.append(min_money_backers)
print("최대 금액 후원자수",max_money_backers)
print("최소 금액 후원자수",min_money_backers)
print('\n')
time.sleep(0.2)
전체 feature 수집되는 형식
실패한 프로젝트 모든 feature 수집 코드를 돌린 후 나오는 결과
5-1-2. csv파일로 수집한 모든 featrue 저장
import pandas as pd
fail_list = []
result_fail = []
for money_list,pledged_money_list,creator_list,backer_list,created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list in zip(money_list,pledged_money_list,creator_list,backer_list,created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list):
fail_list = [money_list,pledged_money_list,creator_list,backer_list,created_list,city_list,category_list,support_bankroll_list,support_max_money_list,support_min_money_list,level_num_list,support_backers_list,support_max_backers_list,support_min_backers_list]
result_fail.append(fail_list)
df_fail = pd.DataFrame(result_fail, columns = ['money','pledged_money','creator','backers','Number of projects opened','Producer area','genre','Support amount list','The highest amount of support','The minimum amount of support','Total number of support steps','List of supporters','Maximum amount of sponsors','Minimum amount of sponsors'])
df_fail.to_csv('fail_link_feature.csv',encoding = 'utf-8-sig')
이번 포스팅에서는 수집한 link에서 개발자도구와 python을 이용해 모든 feature 추출을 해보았습니다.
이 글을 보시는 분들은 이 내용에 대한 정보가 필요해서 들어오셨겠죠?
본인이 직접 스스로 해보시면 살-짝 재미를 느끼실수도있어요!!!
다음시간에는 수집한 데이터들을 가지고 decision tree를 이용해 데이터 분석을 해보겠습니다.
긴 글 봐주셔서 감사드립니다
다들 행복한 하루 보내시길 바랄께요!
[빅데이터] kickstarter에서 Project에 큰 영향을 미치는 Feature 확인하기(3. Decision tree를 이용한 데이터 분석)
- 사실 구글 애드센스 신청이 승인 될 가능성이 적은데 그래도 한 번......혹시나 해서................ 그냥 경험삼아......... 신청해봤습니다.................
- 구글 애드센스 신청하고 2주간 승인 검토가 진행되는데 그 때 동안 1000~1200자 정도의 글을 매일 작성하면 가능성이 쪼콤 높아진다해서 부지런히 쓰는 중입니다...^^
오늘은 작은비버가 학교에서 프로젝트 겸 공부한 내용'kickstarter'사이트를 이용한 빅데이터 분석에 대해 설명드리려고 합니다.
이번 프로젝트는 저번 사랑스러운 제 팀원들과는 다른 사랑스러운 팀원들과 함께 했습니다.
<하고픈 프로젝트 제안서>
저희는 kickstarter에서 성공한 프로젝트,실패한 프로젝트의 데이터를 수집해서 어떠한Feature가 프로젝트 성공여부에 크게 영향을 끼치는지Decision tree를 이용해 분석해 볼려고 합니다.
분석하고자 하는 데이터는 상품명, 후원자수, 제작자 이름, 목표금액, 실제로 모인 금액, 성공여부(성공: 1,실패: 0),제작자의 프로젝트 개설횟수, 제작자 지역, 프로젝트 장르, 서포트 금액,서포트 금액에 따른 구성품을 추출해서 분석하려고 합니다.
킥스타터 프로젝트 메인
자 이제 시작해보자!!!!!!!!!!!!
킥스타터(kickstarter)란?
그 전에 kickstarter를 모르시는 분들이 있을것같아서 설명드리자면 킥스타터는 미국의 크라우드 펀딩 사이트입니다.
우리나라의 텀블벅을 떠올리면 쉽게 이해할 수 있으실 텐데요.투자자는 관심 있는 프로젝트에 돈을 제공하고 펀딩진행자는 그 금액에 따른 보상을 제공하는 형태입니다.돈이 아닌 해당 시제품,감사 인사,작가와의 식사 등 유무형 형태의 보상을 받는 것이 이 킥스타터의 가장 큰 특징입니다.
킥스타터 메인텀블벅과 비슷한 크라우드 펀딩 형식
1. 분석방법
저희는 크라우드 펀딩 데이터를 수집하여‘Decision tree’로‘어떤feature가 프로젝트 성공 여부에 가장 큰 영향을 끼치는지’확인해볼 계획입니다.또한, tree를 만드는 결정에 각 특성이 얼마나 중요한지 평가하는’ feature importance특성 중요도를’이용해 각 특성의 중요도를 확인해볼 계획입니다.
2. 수집방법
1. 성공, 실패한 프로젝트 상세사이트 LINK 수집 각 프로젝트의 상세 페이지로 접근하기 위해 URL수집
상세사이트 link수집
성공한 프로젝트는 단순 URL 접근으로 링크 크롤링 진행
실패한 프로젝트는 로그인한 후, 프로젝트를 saved해야함
Saved한 프로젝트에서 프로젝트의 실패 여부를 확인할 수 있음
-모금액이 75% 이하이고 마감기한이 3일 이내인 프로젝트를 saved 하여 그 중 실패한 프로젝트를 수집하였습니다.
-셀레니움에서 자동 로그인을 하여saved된 프로젝트 중 실패한 프로젝트를 가지고URL상세 페이지를 크롤링하였습니다.
카테고리 검색을 통해 successful project 검색 및 link 수집 진행saved한 프로젝트, 성공 실패 여부 확인 가능
3. 수집 진행 코드 및 수집 데이터
개발자도구에서 link를 나타내는 a태그 확인
python코드로 a 태그 link 수집
3-1. 수집하는 코드 일부분(성공한 프로젝트 링크 수집)
number = [1,2,3,4,5,6,7,8,9,10] #세부 사이트 들어가는 링크 크롤링
success_link_list = list()
for i in number:
url="https://www.kickstarter.com/discover/advanced?state=successful&woe_id=0&sort=magic&seed=2653556&page="+str(i)
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
a_tags = soup.find_all("a", {'class':"block img-placeholder w100p"})
for line in a_tags :
title=line["href"]
success_link_list.append(title)
print(success_link_list)
3-2. 수집하는 코드 일부분(실패한 프로젝트 링크 수집)
fail_link_list = list()
driver.get('https://www.kickstarter.com/login?ref=nav')
driver.find_element_by_id('user_session_email').send_keys('본인 이메일 아이디')
driver.find_element_by_id('user_session_password').send_keys('비밀번호')
xpath = """//*[@id="new_user_session"]/fieldset/ol/li[3]/input"""
driver.find_element_by_xpath(xpath).click()
url="https://www.kickstarter.com/profile/saved_projects?ref=user_menu"
driver.get(url)
time.sleep(0.2)
body = driver.find_element_by_tag_name("body")
num = 100
while num:
body.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
num -= 1
try:
driver.find_element_by_xpath("""//*[@id="react-container"]/div[2]/div[3]/div/button""").click()
except:
None
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
a_tags = soup.find_all("a", {'class':"block img-placeholder w100p"})
for line in a_tags :
title = line["href"]
print(title)
fail_link_list.append(title)
- 로그인을 통해 제가 saved한 프로젝트에서 링크를 수집해야해서 자동로그인을 통해 로그인을 한 후 데이터를 수집하였습니다.
- 저기 로그인 하는 부분에는 본인의 kickstarter의 id 및 비밀번호를 입력하시고 코드 돌리시면 됩니다.